操作系统
1. 进程/线程
- 进程:资源分配的最小单位。
- 线程:程序执行的最小单位。
1.1 PCB
PCB 是操作系统管理进程的核心数据结构,每一个进程(包括子进程)在内存中都对应一个 PCB,它相当于进程的 “身份证 + 档案”,记录了进程的所有关键信息。
PCB 中包含的核心信息
- 进程标识:进程 ID(PID),唯一标识一个进程(如父进程 ID(PPID)用于区分父子关系)。
- 状态信息:进程当前的状态(运行、就绪、阻塞等),操作系统根据状态调度进程。
- 内存信息:进程的内存地址空间(如代码段、数据段、堆、栈的起始和结束地址)。
- 资源信息:打开的文件描述符、占用的 I/O 设备、信号量等资源列表。
- CPU 上下文:进程切换时需要保存的 CPU 寄存器值(如程序计数器 PC、栈指针 SP),确保下次调度时能继续执行。
- 优先级:进程的调度优先级,决定 CPU 分配的优先级。
PCB 的作用
- 进程管理的 “唯一凭证”:操作系统通过 PCB 识别进程、调度进程、回收进程资源。
- 进程切换的 “快照”:当 CPU 从一个进程切换到另一个时,会将当前进程的 CPU 上下文保存到 PCB,再从目标进程的 PCB 中恢复上下文,实现 “无缝切换”。
1.2 TCB
TCB(Thread Control Block,线程控制块)是操作系统管理线程的核心数据结构,类似于进程的 PCB(Process Control Block),但专门用于记录线程的关键信息。线程作为进程内的执行单元,其状态、资源和调度依赖 TCB 进行管理。
TCB 中包含的关键信息(因为线程共享进程资源,无需记录全局资源信息)
线程标识信息:线程 ID(TID):系统分配的唯一标识符,用于区分同一进程内的不同线程;所属进程 ID(PID):关联到线程所属的进程(通过 PID 找到对应的进程 PCB),表明线程与进程的从属关系。
线程状态信息:当前状态:与进程类似,线程也有运行态、就绪态、阻塞态等(如等待锁、I/O 时进入阻塞态);优先级:线程的调度优先级(可能与进程优先级相关,但可独立设置)。
CPU 上下文信息: 寄存器值:包括程序计数器(PC,记录下一条要执行的指令地址)、栈指针(SP,指向线程私有栈的栈顶)、通用寄存器等;线程切换时,这些信息会被保存到 TCB,再次调度时从 TCB 恢复,保证线程能继续执行(与 PCB 的 CPU 上下文作用相同,但线程上下文更轻量)。
线程私有资源:私有栈指针:线程拥有独立的栈(用于函数调用、局部变量存储),TCB 记录栈的地址范围;线程局部存储(TLS):线程私有的全局变量(如
thread_local修饰的变量)的地址信息。同步与通信信息:持有的锁 / 信号量:记录线程当前持有的互斥锁、条件变量等同步资源(用于死锁检测或资源回收);阻塞原因:若线程处于阻塞态,记录阻塞原因(如等待某个锁、等待 I/O 完成)。
1.3 PCB/TCB对比
| 对比维度 | TCB(线程控制块) | PCB(进程控制块) | 关联逻辑 |
|---|---|---|---|
| 管理对象 | 单个线程 | 整个进程(包含所有线程) | 一个 PCB 对应多个 TCB(一个进程可创建多个线程),所有 TCB 通过 PID 关联到同一个 PCB。 |
| 资源记录 | 仅记录线程私有信息(栈、寄存器、TID) | 记录进程全局共享资源(内存空间、文件描述符、设备权限) | 线程需要访问全局资源时(如读文件),通过 TCB 中的 PID 找到所属进程的 PCB,再从 PCB 中获取资源。 |
| 生命周期 | 随线程创建而创建,随线程终止而销毁 | 随进程创建而创建,随进程终止而销毁 | 进程终止时,操作系统会先销毁所有线程的 TCB,再销毁进程的 PCB(回收全局资源)。 |
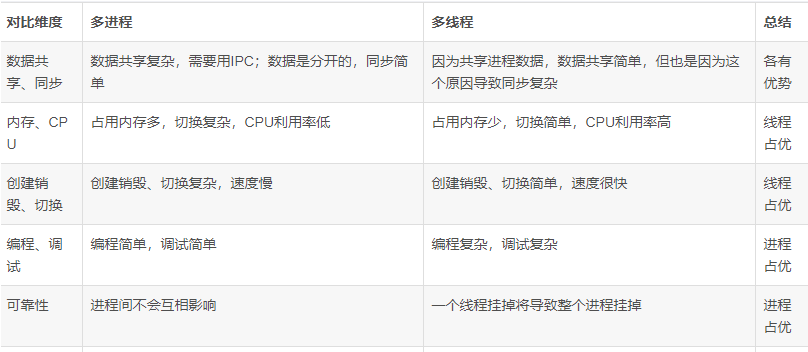
2. 多进程/多线程
多进程:多个独立的进程同时执行,每个进程有自己的地址空间,互不干扰。
多线程:在单个进程内同时执行多个线程,线程是进程的子集,多个线程共享进程的资源。
资源管理:
- 多线程:线程间共享内存和文件描述符,通信相对简单,但同步复杂。
- 多进程:进程间数据是分开的,使用进程间通信(IPC)来共享数据,通信相对复杂,但同步简单。
优缺点:
- 多线程:执行效率高,创建和切换开销小,但一个线程崩溃可能导致整个进程崩溃。
- 多进程:更健壮,一个进程崩溃不会影响其他进程,但资源消耗大,切换开销高。
线程共享内存空间;进程的内存是独立的;
同一个进程的线程之间可以直接交流;两个进程想通信,必须通过一个中间代理来实现
3. 进程间通信
- 进程间通信(IPC,Inter-Process Communication)是操作系统中多个进程交换数据、协同工作的核心机制。不同的 IPC 方式适用于不同的场景,其设计原理、性能和适用范围差异较大。
- 进程是操作系统分配资源的基本单位,且具有 “地址空间隔离” 特性(一个进程的内存、数据,其他进程默认看不到)
- 进程通信就是专门解决 “进程间需要传递数据、指令或状态” 的机制 —— 本质是打破隔离,实现信息交换。
- 进程通信的典型场景:
- 播放器进程(如 PotPlayer)向字幕进程(如 SubtitleEdit)传递 “当前播放时间戳”;
- 终端进程(如 CMD)向后台服务进程(如 MySQL)传递 “查询 SQL 指令”;
- 手机微信进程向系统通知进程传递 “新消息内容”。
- 常见进程间通信方式及原理如下
3.1 管道
- 管道(Pipeline)
- 原理:管道是一种特殊的文件(存在于文件系统中),进程通过读写该文件实现通信。本质是内核中的一段环形缓冲区,内核会维护一个缓冲区,通过 “读 / 写” 操作实现进程间字节流传递,本质是 “文件描述符” 的抽象。
- 分类
- 匿名管道(Pipe):仅用于父子进程或亲缘进程(如 fork 创建的子进程),生命周期随进程结束而销毁,无文件名,通过pipe()系统调用创建。
- 命名管道(FIFO):可用于非亲缘进程,通过文件系统中的路径(如/tmp/myfifo)标识,生命周期独立于进程,通过mkfifo()创建,读写方式与文件一致。
- 实际应用
- 匿名管道:Shell 中的管道命令(如ls -l | grep .txt),父进程(ls)写入数据,子进程(grep)读取,实现命令协作。
- 命名管道:本地服务间的简单通信,如日志收集(应用进程写入日志到 FIFO,日志进程从 FIFO 读取并存储)。
- 典型场景:轻量、单向、低延迟的本地进程通信,无需跨网络。
3.2 信号
- 信号(Signal)
- 原理:操作系统向进程发送的异步事件通知(类似 “软件中断”),可携带极少信息(仅信号编号),用于触发进程预设的处理函数。主要用于通知进程某些事件的发生,常见的信号有 SIGINT、SIGTERM 等。
- 举例
- 常见信号:SIGINT(Ctrl+C 终止)、SIGKILL(强制杀死进程)、SIGCHLD(子进程退出通知)。
- 进程通过signal()或sigaction()注册信号处理函数。
- 实际应用
- 异常处理:进程崩溃时通过SIGSEGV(段错误)捕获并记录日志(如 Linux 的 core dump)。
- 进程控制:父进程通过SIGTERM优雅终止子进程(子进程收到后释放资源再退出)。
- 典型场景:简单的事件通知(如进程退出、超时提醒),不适合传递复杂数据。
3.3 消息队列
- 消息队列(Message Queue)
- 消息队列是为了克服信号传递信息量少,管道只能承载无格式字节流以及缓冲区大小受限等问题而设计的。
- 消息队列允许进程以消息的形式发送和接收数据,每条消息都有一个类型标识,这使得消息队列比管道更灵活,可以使用 msgget、msgsnd 和msgrcv 等系统调用来操作消息队列。
- 原理:内核维护的消息链表,进程可按 “类型” 发送 / 接收消息(消息包含类型和数据),支持异步通信,无需进程同步等待。
- 使用方法
- 发送方通过msgsnd()将消息放入队列,接收方通过msgrcv()按类型提取消息(可过滤特定类型)。
- 消息有大小限制(通常几 KB),队列总容量有限制。
- 实际应用
- 分布式任务调度:如公司内部的任务分配系统(调度进程向队列发送任务, Worker 进程按类型领取任务)。
- 异步通知:电商订单系统中,支付进程完成后向消息队列发送 “支付成功” 消息,物流进程监听并处理。
- 局限性:不适合高频、大数据量场景(性能低于共享内存),目前逐步被分布式消息中间件(如 RabbitMQ)替代。
3.4 共享内存
共享内存(Shared Memory)
原理:多个进程将同一块物理内存映射到各自的虚拟地址空间,直接读写内存实现通信,是速度最快的 IPC 方式(无需内核中转数据)。
共享内存通过 shmget、shmat 和 shmdt 等系统调用进行管理。进程可以创建或附加到一个共享内存段,然后对该内存段进行读写操作。
同步机制:由于多个进程可以同时访问同一块内存,需要依靠某种同步机制来保证数据的一致性和避免竞争条件。共享内存非常高效,但需要小心处理同步和互斥问题,否则可能导致数据不一致或竞争条件。
高速通信:由于数据直接存取,共享内存的速度非常快,适合需要大量数据交换的场景。
使用方式
- 需配合同步机制(如信号量)防止并发读写冲突。
- 通过shmget()(创建)、shmat()(映射到进程)等系统调用实现。
实际应用
- 高频实时数据交换:金融交易系统(如股票行情推送,行情服务器将实时价格写入共享内存,多个交易进程直接读取,延迟 < 1ms)。
- 大型数据共享:视频处理软件(如 Adobe Premiere,多个滤镜进程共享同一视频帧数据,避免数据拷贝)。
- 典型公司:高频交易公司(如 Jump Trading)、实时渲染引擎(如 Unity 引擎的多进程渲染)。
3.5 信号量
- 信号量(Semaphore)
- 原理:内核维护的计数器,用于控制多个进程对共享资源的访问(同步 / 互斥),本身不传递数据,仅用于 “权限控制”。
- 用法
- P 操作:计数器 - 1,若计数器 < 0 则阻塞进程(等待资源)。
- V 操作:计数器 + 1,若有进程阻塞则唤醒一个。
- 常用于保护共享内存、消息队列等资源的并发访问。
- 实际应用
- 共享资源互斥:多进程读写同一数据库文件时,通过信号量保证 “同一时间只有一个进程写入”。
- 生产者 - 消费者模型:如电商库存系统(生产者进程增加库存,消费者进程减少库存,信号量控制库存不为负)。
3.6 套接字
- 套接字(Socket)
- 原理:基于网络协议栈的通信机制,支持同一主机或跨网络的进程通信,通过 “IP 地址 + 端口” 标识进程,支持 TCP(可靠流)和 UDP(不可靠报)协议。
- 套接字提供了一种标准化的通信机制,允许不同主机上的进程进行通信,可以使用 socket、bind、listen、accept、connect 等系统调用来操作套接字。套接字支持多种通信协议,如 TCP 和 UDP 。
- 套接字是网络编程的基础,广泛应用于客户端-服务器模型的应用程序中。
- 使用方式
- 本地套接字(Unix Domain Socket):用于同一主机进程,通过文件系统路径标识(如/var/run/mysocket),性能优于网络套接字。
- 网络套接字:用于跨主机通信,如互联网服务。
- 实际应用
- 跨主机通信:所有互联网服务(如浏览器与 Web 服务器通过 TCP 通信,即时通讯工具如微信用 UDP 传输语音)。
- 本地高可靠通信:数据库客户端与服务端(如 MySQL 客户端通过本地 Socket 连接服务器,避免网络开销)。
- 典型公司:腾讯(微信消息传输)、阿里(分布式服务间调用)、谷歌(跨数据中心通信)。
3.7 适用场景
| 场景 | 主流方式 | 核心技术 / 库 | 典型业务 |
|---|---|---|---|
| 本地轻量通信 | 命名管道(FIFO)、本地 Socket | mkfifo()、socket(AF_UNIX)、Qt 的QLocalSocket | 日志收集、桌面应用插件通信 |
| 高频实时数据交换 | 共享内存 + 信号量 | System V 共享内存、boost::interprocess | 金融行情、实时渲染 |
| 跨网络 / 跨主机通信 | 网络 Socket(TCP/UDP) | BSD Socket、Boost.Asio、Qt 的QTcpSocket | 互联网服务、分布式系统 |
| 异步消息传递 | 消息队列(分布式中间件) | RabbitMQ、Kafka(基于 Socket 封装) | 电商订单、日志异步处理 |
| 简单事件通知 | 信号(Signal) | sigaction()、Qt 的QProcess::errorOccurred |
3.8 IPC-C++原生及标准库
- 管道 / 命名管道:通过pipe()(匿名)、mkfifo()(命名)+ open()/read()/write()系统调用,适合轻量通信。
- 共享内存:shmget()/shmat()(System V)或mmap()(POSIX),配合sem_init()(信号量)同步,适合高性能场景。
- Socket:通过 BSD Socket API(socket()/connect()/send())实现,跨平台需处理 Windows/Linux 差异。
- 第三方库:Boost.Interprocess(封装共享内存、消息队列)、Boost.Asio(跨平台 Socket 通信),解决原生 API 的跨平台问题。
3.9 Qt中IPC封装
| IPC 方式 | Qt 类 / 方法 | 适用场景 |
|---|---|---|
| 父子进程管道通信 | QProcess | 主进程启动子进程并传递命令 / 数据(如 IDE 调用编译器)。 |
| 本地 Socket 通信 | QLocalServer/QLocalSocket | 同一主机非亲缘进程(如桌面应用与后台服务)。 |
| 网络 Socket 通信 | QTcpServer/QTcpSocket、QUdpSocket | 跨主机通信(如客户端 - 服务器应用)。 |
| 共享内存 | QSharedMemory | 高频数据共享(如多窗口应用共享大型缓存)。 |
| 信号量同步 | QSemaphore | 配合共享内存控制并发访问。 |
4. 进程间共享资源
“资源” 是操作系统提供的可利用对象(如内存块、文件、设备、端口等)。“进程间共享资源” 指的是 “多个进程不需要交换数据,而是需要共同访问同一个资源”—— 本质是复用资源,避免重复创建 / 浪费,或 “协同操作同一个对象”。
共享资源” 的典型场景
- 多个浏览器进程(如 Chrome 的多标签页进程)共享同一个 “系统字体文件”(不需要传递数据,只是都要读字体来渲染页面);
- 多个办公软件进程(如 Word、Excel)共享同一个 “打印机设备”(不需要传递数据,只是都要使用打印机打印);
- 多个后端服务进程(如 Nginx 的 worker 进程)共享同一个 “监听端口(如 80 端口)”(不需要传递数据,只是都要接收客户端请求)。
共享内存既是 “共享资源”,也能用于 “进程通信”,但需明确:
- 当多个进程只是读共享内存里的配置数据(如系统全局配置),不传递新数据时:这是 “共享资源”(目的是复用配置,无信息交换);
- 当进程 A 往共享内存写 “数据 X”,进程 B 读 “数据 X” 并回复 “数据 Y” 时:这是 “进程通信”(目的是交换 X 和 Y,共享内存只是 “通信的载体”)。
- 简言之:共享内存是 “资源”,用它做什么(传数据 / 复用)才决定了属于 “通信” 还是 “共享资源”—— 二者的核心区别仍在 “目的”,而非 “载体”。
所有共享资源技术的本质是 “让多进程无需重复创建资源,直接复用同一对象”,按资源类型可分为 4 大类:
- 文件类共享资源:复用磁盘 / 文件系统中的对象
- 设备类共享资源:复用硬件 / 系统设备
- 内存类共享资源:复用物理内存块 / 共享内存
- 其他系统级共享资源:复用系统统一管理的对象
[!NOTE] 通信是 “传东西”,共享资源是 “用东西”
5. 线程间通信
- 同一进程的线程共享地址空间,没有通信的必要,但要做好同步/互斥,保护共享的全局变量。
- 线程间的通信目的主要是用于线程同步,由于线程共享进程内存,线程间通信的核心目的不是 “传递数据”(数据可直接共享),线程没有像进程通信中的用于数据交换的通信机制,而是用于线程同步,核心是传递 “状态 / 事件”(如 “任务已完成”“数据已就绪”),实现线程间的协作。
5.1 共享内存
- 速度快,线程之间直接访问共享内存区域,无需中介。支持大数据量的传输,因为内存空间可以非常大。
- 需要额外的同步机制(如互斥锁、读写锁等)来避免多个线程同时访问同一内存区域,从而导致数据不一致,如果没有恰当的同步,可能会出现数据竞争或死锁问题。
5.2 共享变量
- 共享变量是最简单的线程间通信方式之一。它可以通过多个线程共享相同的内存空间来实现。当一个线程修改了共享变量时,其他线程也能看到这个变化。这种方式的好处是实现简单,但是同时也带来了一些问题。由于多个线程都可以访问和修改同一个变量,可能会导致数据的不一致性,需要使用互斥锁等机制来保证线程安全。
5.3 锁机制
- 互斥锁是一种保护共享资源的机制。它可以确保在任何时候只有一个线程可以访问共享资源。当一个线程获得了互斥锁,其他线程就必须等待直到这个线程释放锁为止。互斥锁是保证线程安全的一种重要方式。在多线程的环境中,共享资源可能会被多个线程同时访问和修改,如果没有互斥锁的保护,就可能会导致数据的不一致性或者其他问题。
- 读写锁是可以同时读,但是只能单个线程写
5.4 条件变量
- 条件变量是一种线程间通信的高级方式。它可以使得一个线程在等待某个条件变为真时暂停执行,并在另一个线程中满足条件时恢复执行。条件变量通常与互斥锁一起使用,因为等待条件变量时需要先释放互斥锁。
- 可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
- 例如,在一个生产者和消费者模型中,生产者线程生产了一些数据,但是消费者线程尚未准备好接收这些数据。生产者线程可以使用条件变量来等待消费者线程准备好接收数据。当消费者线程准备好时,它可以使用条件变量来通知生产者线程可以继续生产数据了。条件变量还可以用于其他场景,比如线程池、任务队列等。
5.5 信号量
- 通过 “计数器” 实现线程间的同步通信(如控制同时运行的线程数量、传递 “资源可用” 信号)。
- 例:用信号量控制 “生产者 - 消费者” 模型,生产者生产后 “增加计数”,消费者消费前 “等待计数 > 0”。
5.6 消息队列
线程之间的通信是异步的,发送线程不需要等待接收线程处理完消息,可以继续执行其他任务。
支持多对多的通信模式,多个线程可以将消息放入队列,多个线程可以从队列中读取消息。
需要管理消息队列的同步问题,以避免消息丢失或重复。
例子:一个线程将处理任务放入消息队列,另一个线程从消息队列中取出任务并处理,适用于任务调度场景。
5.7 管道
- 管道是一种单向通信机制。它可以将一个进程的输出连接到另一个进程的输入,从而实现进程间通信。管道可以用于多线程编程中的进程间通信,也可以用于不同机器之间的通信。
- 例如,在一个多线程的web服务器中,可以使用管道将请求处理线程的输出连接到响应处理线程的输入。这可以避免线程之间的数据竞争,提高系统的性能。
6. 线程间共享资源
线程间共享资源:天然的内存共享(最核心的特性)
线程是进程内的执行单元,同一进程的所有线程共享该进程的全部内存资源(包括全局变量、堆内存、静态变量等),这是线程与进程(地址空间隔离)最本质的区别。
线程间共享的资源类型(默认即可共享,无需额外机制)
- 全局变量 / 静态变量:进程内的全局内存区由所有线程共享(如
int g_count;、static int s_data;); - 堆内存:通过
new/malloc分配的堆内存,所有线程都可访问(如int* ptr = new int[10];,任意线程都能通过ptr操作); - 文件描述符 / 句柄:进程打开的文件、网络连接等句柄,所有线程共享(如一个线程打开的文件,其他线程可直接读写);
- 代码段 / 常量区:进程的代码和常量(如字符串常量)由所有线程共享。
- 全局变量 / 静态变量:进程内的全局内存区由所有线程共享(如
共享的优势:线程间共享数据无需像进程那样 “显式传递”,直接通过内存访问,效率极高(无数据拷贝)
共享的问题:多线程并发读写共享资源时,会导致数据竞争(Data Race)(如两个线程同时修改同一变量,结果不可预测),因此必须配合互斥锁(如
std::mutex) 等同步机制保护。
7. 分布式
集群是指在几个服务器上部署相同的应用程序来分担客户端的请求。它是同一个系统部署在不同的服务器上,比如一个登陆系统部署在不同的服务器上。(类似于多个人一起做同样的事)集群主要的使用场景是为了分担请求的压力。但是,当压力进一步增大的时候,可能在需要存储的部分,比如mysql无法面对大量的“写压力”。因为在mysql做成集群之后,主要的写压力还是在master的机器上,其他slave机器无法分担写压力,这时,就引出了“分布式”。
分布式是指多个系统协同合作完成一个特定任务的系统。它是不同的系统部署在不同的服务器上,服务器之间相互调用。(类似于多个人一起做不同的事)分布式是解决中心化管理的问题,把所有的任务叠加到一个节点处理,太慢了。所以把一个大问题拆分为多个小问题,并分别解决,最终协同合作。分布式的主要工作是分解任务,把职能拆解。
分布式的主要应用场景是单台机器已经无法满足这种性能的要求,必须要融合多个节点,并且节点之间的相关部分是有交互的。相当于在写mysql的时候,每个节点存储部分数据(分库分表),这就是分布式存储的由来。存储一些非结构化数据:静态文件、图片、pdf、小视频 ... 这些也是分布式文件系统的由来。
分布式系统是若干独立计算机的集合,这计算机对用户来说就像单个相关系统。也就是说分布式系统背后是由一系列的计算机组成的,但用户感知不到背后的逻辑,就像访问单个计算机一样。
在分布式系统中: 1、应用可以按业务类型拆分成多个应用,再按结构分成接口层、服务层;我们也可以按访问入口分,如移动端、PC端等定义不同的接口应用; 2、数据库可以按业务类型拆分成多个实例,还可以对单表进行分库分表; 3、增加分布式缓存、搜索、文件、消息队列、非关系型数据库等中间件;
很明显,分布式系统可以解决集中式不便扩展的弊端,我们可以很方便的在任何一个环节扩展应用,就算一个应用出现问题也不会影响到别的应用。
集群是个物理形态,分布式是个工作方式。
分布式计算系统具有如下特点:
- 资源共享:分布式系统可以共享硬件、软件或数据
- 并行处理:多台机器可以同时处理同一功能
- 支持扩展:当扩充到其他计算机时,计算和处理能力可以按需进行扩展
- 错误检测:可以更轻松地检测故障
- 公开透明:节点可以访问系统中的其他节点并与之通信
分布式系统分为分布式计算(computation)与分布式存储(storage)。计算与存储是相辅相成的,计算需要数据,要么来自实时数据(流数据),要么来自存储的数据;而计算的结果也是需要存储的。在操作系统中,对计算与存储有非常详尽的讨论,分布式系统只不过将这些理论推广到多个节点罢了。将任务分片(MapReduce),每个节点存一部分数据(Partition)。
单个节点的故障(进程crash、断电、磁盘损坏)是个小概率事件,但整个系统的故障率会随节点的增加而指数级增加,网络通信也可能出现断网、高延迟的情况。在这种一定会出现的“异常”情况下,分布式系统还是需要继续稳定的对外提供服务,即需要较强的容错性。最简单的办法,就是冗余或者复制集(Replication),即多个节点负责同一个任务。
分布式系统挑战
- 异构的机器与网络
- 普遍的节点故障
- 不可靠的网络
7.1 案例
假设这是一个对外提供服务的大型分布式系统,用户连接到系统,做一些操作,产生一些需要存储的数据,这是一个复杂的过程
用户使用Web、APP、SDK,通过HTTP、TCP连接到系统。在分布式系统中,为了高并发、高可用,一般都是多个节点提供相同的服务。那么,第一个问题就是具体选择哪个节点来提供服务,这个就是负载均衡(load balance)。只要涉及到多个节点提供同质的服务,就需要负载均衡。
通过负载均衡找到一个节点,接下来就是真正处理用户的请求,请求有可能简单,也有可能很复杂。简单的请求,比如读取数据,那么很可能是有缓存的,即分布式缓存,如果缓存没有命中,那么需要去数据库拉取数据。对于复杂的请求,可能会调用到系统中其他的服务。
假设服务A需要调用服务B的服务,首先两个节点需要通信,网络通信都是建立在TCP/IP协议的基础上。但是,每个应用都手写socket是一件冗杂、低效的事情,因此需要应用层的封装,因此有了HTTP、FTP等各种应用层协议。
当系统愈加复杂,提供大量的http接口也是一件困难的事情。因此,有了更进一步的抽象,那就是RPC(remote produce call),是的远程调用就跟本地过程调用一样方便,屏蔽了网络通信等诸多细节,增加新的接口也更加方便。
一个请求可能包含诸多操作,即在服务A上做一些操作,然后在服务B上做另一些操作。比如简化版的网络购物,在订单服务上发货,在账户服务上扣款。这两个操作需要保证原子性,要么都成功,要么都不操作。这就涉及到分布式事务的问题,分布式事务是从应用层面保证一致性:某种守恒关系。
上面说道一个请求包含多个操作,其实就是涉及到多个服务,分布式系统中有大量的服务,每个服务又是多个节点组成。那么一个服务怎么找到另一个服务(的某个节点呢)?通信是需要地址的,怎么获取这个地址,最简单的办法就是配置文件写死,或者写入到数据库。但这些方法在节点数据巨大、节点动态增删的时候都不大方便,这个时候就需要服务注册与发现:提供服务的节点向一个协调中心注册自己的地址,使用服务的节点去协调中心拉取地址。
从上可以看见,协调中心提供了中心化的服务:以一组节点提供类似单点的服务,使用非常广泛,比如命令服务、分布式锁。协调中心最出名的就是chubby,zookeeper。
回到用户请求这个点,请求操作会产生一些数据、日志,通常为信息,其他一些系统可能会对这些消息感兴趣。比如个性化推荐、监控等,这里就抽象出了两个概念,消息的生产者与消费者。那么生产者怎么将消息发送给消费者呢,RPC并不是一个很好的选择,因为RPC肯定得指定消息发给谁。
但实际的情况是生产者并不清楚、也不关心谁会消费这个消息,这个时候消息队列就出马了。简单来说,生产者只用往消息队列里面发就行了,队列会将消息按主题(topic)分发给关注这个主题的消费者。消息队列起到了异步处理、应用解耦的作用。
上面提到,用户操作会产生一些数据,这些数据忠实记录了用户的操作习惯、喜好,是各行各业最宝贵的财富。比如各种推荐、广告投放、自动识别。这就催生了分布式计算平台,比如Hadoop,Storm等,用来处理这些海量的数据。
最后,用户的操作完成之后,用户的数据需要持久化,但数据量很大,大到按个节点无法存储。那么这个时候就需要分布式存储:将数据进行划分放在不同的节点上,同时,为了防止数据的丢失,每一份数据会保存多分。
传统的关系型数据库是单点存储,为了在应用层透明的情况下分库分表,会引用额外的代理层。而对于NoSql,一般天然支持分布式。
7.2 组件
- 负载均衡: Nginx:高性能、高并发的web服务器;功能包括负载均衡、反向代理、静态内容缓存、访问控制;工作在应用层 LVS:Linux virtual server,基于集群技术和Linux操作系统实现一个高性能、高可用的服务器;工作在网络层
- webserver: Java:Tomcat,Apache,Jboss Python:gunicorn、uwsgi、twisted、webpy、tornado
- service: SOA、微服务、spring boot,django
- 容器: docker,kubernetes
- cache: memcache、redis等
- 协调中心: zookeeper、etcd等 zookeeper使用了Paxos协议Paxos是强一致性,高可用的去中心化分布式。zookeeper的使用场景非常广泛,之后细讲。
- rpc框架: grpc、dubbo、brpc dubbo是阿里开源的Java语言开发的高性能RPC框架,在阿里系的诸多架构中,都使用了dubbo + spring boot
- 消息队列: kafka、rabbitMQ、rocketMQ、QSP 消息队列的应用场景:异步处理、应用解耦、流量削锋和消息通讯
- 实时数据平台: storm、akka
- 离线数据平台: hadoop、spark PS: apark、akka、kafka都是scala语言写的,看到这个语言还是很牛逼的
- dbproxy: cobar也是阿里开源的,在阿里系中使用也非常广泛,是关系型数据库的sharding + replica 代理
- db: mysql、oracle、MongoDB、HBase
- 搜索: elasticsearch、solr
- 日志: rsyslog、elk、flume
7.3 CAP
分布式系统有 3 个核心需求,但任何情况下都只能满足其中 2 个,无法三者兼顾,这是分布式的 “铁律”。3 个需求分别是:
C(Consistency,一致性):所有机器的同一份数据,必须同时一样(比如库存改了,所有服务器立刻看到新库存);
A(Availability,可用性):只要不是所有机器都坏了,系统就能正常干活(比如用户下单,不管哪台服务器处理,都能成功);
P(Partition Tolerance,分区容错性):网络断了(比如北京的服务器和上海的服务器连不上),系统也能继续工作(北京的用户还能下单,上海的用户也能下单)。
分析:比如网络断了(必须满足 P):如果要保证 C(一致性),就必须让两边服务器暂停干活(等网络恢复再同步数据),但这样 A(可用性)就没了;如果要保证 A(可用性),两边服务器继续干活,数据就会不一致(C 没了)—— 所以只能选 “CP” 或 “AP”。
7.4 分布式锁
控制分布式系统中 “多个机器同时操作同一份数据” 的锁
单机系统里,用 “本地锁”(比如 Java 的 synchronized)就能控制多线程抢资源,但分布式系统里是 “多台机器”(不是同一台机器的线程),本地锁管不了其他机器 —— 这时候就需要 “分布式锁”,让多台机器遵守同一套 “抢资源规则”,提供“锁服务”(比如 Redis)抢锁。
常见的分布式锁实现方案有三种:MySQL分布式锁、ZooKepper分布式锁、Redis分布式锁。
7.4.1 MySQL 分布式锁
用数据库实现分布式锁比较简单,就是创建一张锁表,数据库对字段作唯一性约束。
加锁的时候,在锁表中增加一条记录即可;释放锁的时候删除记录就行。
如果有并发请求同时提交到数据库,数据库会保证只有一个请求能够得到锁。
这种属于数据库 IO 操作,效率不高,而且频繁操作会增大数据库的开销,因此这种方式在高并发、高性能的场景中用的不多。
7.4.2 ZooKeeper
ZooKeeper 的数据节点和文件目录类似,例如有一个 lock 节点,在此节点下建立子节点是可以保证先后顺序的,即便是两个进程同时申请新建节点,也会按照先后顺序建立两个节点。
所以我们可以用此特性实现分布式锁。以某个资源为目录,然后这个目录下面的节点就是我们需要获取锁的客户端,每个服务在目录下创建节点,如果它的节点,序号在目录下最小,那么就获取到锁,否则等待。释放锁,就是删除服务创建的节点。
ZK 实际上是一个比较重的分布式组件,实际上应用没那么多了,所以用 ZK 实现分布式锁,其实相对也比较少。
7.4.3 Redis 实现分布式锁
Redis 实现分布式锁,是当前应用最广泛的分布式锁实现方式。
Redis 执行命令是单线程的,Redis 实现分布式锁就是利用这个特性。
实现分布式锁最简单的一个命令:setNx(set if not exist),如果不存在则更新:
setNx resourceName value加锁了之后如果机器宕机,那这个锁就无法释放,所以需要加入过期时间,而且过期时间需要和 setNx 同一个原子操作,在 Redis2.8 之前需要用 lua 脚本,但是 redis2.8 之后 redis 支持 nx 和 ex 操作是同一原子操作。
set resourceName value ex 5 nx一般生产中都是使用 Redission 客户端,非常良好地封装了分布式锁的 api,而且支持 RedLock。
7.5 分布式事务
分布式系统中,需要 “多个模块(或服务器)一起完成的事务”—— 必须所有模块都成功,整个事务才算成功;只要有一个模块失败,所有模块都要回滚(回到之前的状态)。本质上是将单一库的事务概念扩大到了多库,目的是为了保证跨服的数据一致性。
因为分布式系统中,每个模块独立工作,可能出现 “部分成功、部分失败” 的情况 —— 比如下单时,订单创建成功了,但库存扣减失败了,这就会导致 “有订单没库存”,出大问题。
常见的分布式事务解决方案(0 基础了解名称即可):TCC(Try-Confirm-Cancel)、Saga 模式、本地消息表等 —— 核心思路都是 “要么都成功,要么都回滚”。
7.6 BASE理论
BASE(Basically Available、Soft state、Eventual consistency)是基于 CAP 理论逐步演化而来的,核心思想是即便不能达到强一致性(Strong consistency),也可以根据应用特点采用适当的方式来达到最终一致性(Eventual consistency)的效果。
Basically Available(基本可用):什么是基本可用呢?假设系统出现了不可预知的故障,但还是能用,只是相比较正常的系统而言,可能会有响应时间上的损失,或者功能上的降级。
Soft State(软状态):什么是硬状态呢?要求多个节点的数据副本都是一致的,这是一种“硬状态”。软状态也称为弱状态,相比较硬状态而言,允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
Eventually Consistent(最终一致性):上面说了软状态,但是不应该一直都是软状态。在一定时间后,应该到达一个最终的状态,保证所有副本保持数据一致性,从而达到数据的最终一致性。这个时间取决于网络延时、系统负载、数据复制方案设计等等因素。
8. ROS
ROS(Robot Operating System)机器人操作系统是用于创建机器人应用程序的软件框架,其主要目的是提供可以用于创建机器人应用程序的功能,创建的应用程序也可以被其他机器人再次使用。
ROS 由一系列可以简化机器人软件开发的软件工具、软件库和软件包组成,是 BSD 许可的一个完整的开源项目,可用于研究和商业应用。虽然 ROS 表示机器人操作系统,但它并不是一个真正的操作系统。相反,它是一个提供了真实操作系统功能的元操作系统。
ROS 是管道(消息传递)、开发工具、应用功能和生态系统的组合。ROS 中有强大的开发工具,可以调试和可视化机器人数据。ROS 具有内置的机器人应用功能,如机器人导航、定位、绘图、操作等。它们有助于创建强大的机器人应用程序。
8.1 ROS 提供的主要功能
- 消息传递接口:这是 ROS 的核心功能,它支持进程间通信。使用这种消息传递功能,ROS 程序可以与其链接的系统进行通信并交换数据。
- 硬件抽象:ROS 具有一定程度的抽象,使开发人员能够创建与机器人无关的应用程序。这类应用程序可以用于任何机器人,因此开发人员只需要关心底层的机器人硬件。
- 软件包管理:把 ROS 节点以软件包形式组织在一起,则称为 ROS 软件包。ROS 软件包由源代码、配置文件、构建文件等组成。我们可以创建包、构建包和安装包。ROS 中有一个构建系统,可以帮助构建这些软件包。ROS 的软件包管理使 ROS 的开发更加系统化和组织化。
- 第三方软件库集成:ROS 框架可与许多第三方软件库集成,如 OpenCV、PCL、OpenNI 等。这有助于开发者在 ROS 中创建各种各样的应用程序。
- 底层设备控制:使用机器人工作时,也可能需要使用底层设备,例如控制 I/O 引脚、通过串口发送数据等设备。这也可以使用 ROS 完成。
- 分布式计算:处理来自机器人传感器的数据所需的计算量非常大。使用 ROS 可以轻松地将计算分配到计算节点集群中。分配计算能力使处理数据的速度比使用单个计算机更快。
- 代码复用:ROS 的主要目标是实现代码复用。代码复用促进了全球研发团队的发展。ROS 的可执行文件叫作节点。这些可执行文件被打包成一个实体,叫作 ROS 软件包。一批软件包集合叫作元软件包,软件包和元软件包都可以共享和分发。
- 语言独立性:ROS 框架可以使用当前流行的编程语言(如 Python、C++ 和 Lisp)。节点可以用任何一种语言来编写,并且可以通过 ROS 框架进行无障碍通信。
- 测试简单:ROS 有一个内置的单元/集成测试框架 rostest,用于测试 ROS 软件包。
- 扩展:ROS 可以扩展到机器人中执行复杂的计算。
- 免费且开源:ROS 的源代码是开放的,并且是完全免费的。ROS 的核心部分,经 BSD 协议许可,可以在商业领域和不开源的产品上复用。
9. 计算机硬件
9.1 计组
- 计算机硬件由运算器、控制器、存储器、输入设备和输出设备五大部分组成
- 硬盘:机械硬盘(HDD)、固态硬盘(SSD)